Abordagens simples de Chunking: métodos de tamanho fixo e recursivo
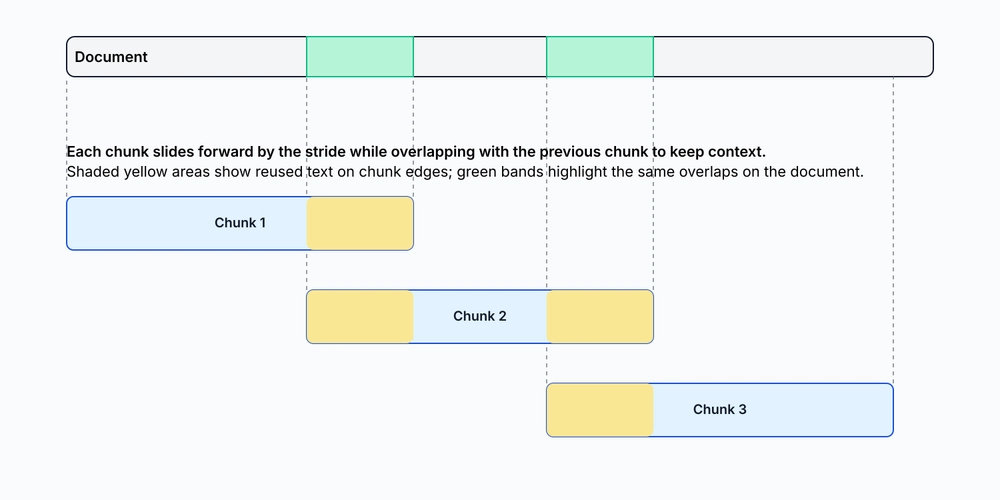
Este é um post cruzado, você pode encontrar o artigo original no meu meio simples médio, é uma técnica fundamental para dividir documentos grandes em peças menores e gerenciáveis sem perder o contexto importante. Neste guia, exploraremos abordagens práticas, incluindo chunking de janelas deslizantes e chunking recursivo, comparando seus pontos fortes e fracos. Os métodos de tamanho fixo consideram o seguinte documento: document = “” “John Doe é o CEO da Examplecorp. Ele é um engenheiro de software qualificado com foco em sistemas escaláveis. Em seu tempo livre, ele toca guitarra e lê a ficção científica. A Sweet Stufforiy é fundada em uma Stufts, em uma empresa, a sede em São Fundos e Financiadores de São Fundação. Exemplo Inc, um conglomerado de tecnologia. A maneira mais simples de reduzir um documento é usar chunking de tamanho fixo. Esse método é relativamente simples: dividimos o documento em pedaços de tamanho fixo. Aqui está como a implementação se parece: def fix_size_chunking (documento, chunk_size): retornar [document[i:i+chunk_size] Para i no intervalo (0, len (document), chunk_size)]chunks = fixo_size_chunking (document, 100) insira modo de saída de tela cheia de tela cheia. on scalable syste” ‘ms.\nIn his spare time, he plays guitar and reads science fiction.\n\nExampleCorp was founded in 2020 a’ ‘nd is based in San Francisco.\nIt builds AI solutions for various industries.\nJohn still finds time f’ Enter fullscreen mode Exit fullscreen mode Note how the word “systems” is split between the first and second Chunk. Com documentos mais longos, isso se tornará um grande problema, pois dividiremos o contexto entre os pedaços e perderão informações importantes. Uma melhoria direta para o chunking de tamanho fixo é o ritmo de janela deslizante, onde cada novo pedaço desliza para a frente, mantendo alguma sobreposição com o pedaço anterior. Isso nos permite manter algum contexto entre os pedaços. Aqui está como a implementação se parece: def sliding_window_chunking (documento, chunk_size, sobreposição): chunks = []
para i no intervalo (0, len (documento), chunk_size – sobreposição): chunks.append (documento[i:i+chunk_size]) Retornar pedaços de pedaços = sliding_window_chunking (documento, 100, 20) Digite o modo de saída de tela cheia da tela cheia aqui estão os três primeiros pedaços: “\ nJohn Doe é o CEO de Examplecorp. Ficção. \ n \ nexampleCorp W ” ‘\ n \ nexampleCorp foi fundada em 2020 e está sediada em São Francisco. O problema com essas duas abordagens é que elas não estão cientes do conteúdo do documento. Eles sempre dividirão o documento no mesmo local, independentemente da estrutura real do documento. O agrupamento recursivo de uma abordagem mais sofisticada é usar o ritmo recursivo, onde definimos uma hierarquia de separadores e usá -los para dividir o documento recursivamente em pedaços menores. Os pedaços onde nos dividimos pela primeira vez pelo separador mais grosseiro e depois nos movemos para os mais refinados até que os pedaços estejam abaixo de um determinado tamanho. Aqui está como a assinatura da função seria: def Rrusive_Chunking (texto, separadores, max_len): … Digite o modo de saída da tela cheia como possível implementar isso? Primeiro, precisaríamos definir o caso base – se o texto já for curto ou não há mais separadores, devolvemos o texto atual como um chunk: se len ( <= max_len or not separators:
return [text]
Enter fullscreen mode
Exit fullscreen mode
Assuming the base case is not met, we proceed with the recursive case by selecting the first (i.e., highest-priority) separator and splitting the text accordingly:
sep = separators[0]
parts = text.split(sep)
Enter fullscreen mode
Exit fullscreen mode
Now, we have a list of parts and we can iterate over each part and check whether it is still too long.If that is the case, then we should recursively chunk the part again with the remaining separators.Otherwise, we can just add the part to the list of chunks.We also need to make sure that we skip empty parts.
This approach follows a classic recursive structure and can be implemented as follows:
for part in parts:
if not part.strip():
continue # Skip empty parts
# If still too long, recurse with other separators
if len(part) > max_len e len (separadores)> 1: chunks.extend (recursive_chunking (parte, separadores[1:]max_len)) # Caso contrário, podemos apenas adicionar a parte à lista de blocos mais: chunks.append (parte) digite o modo de saída de tela cheia Finalmente, precisamos retornar a lista de pedaços da função recursiva. Aqui está como a implementação de toda a função se parece: def recursive_chunking (texto, separadores, max_len): se len (texto) <= max_len or not separators:
return [text]
sep = separators[0]
parts = text.split(sep)
chunks = []
for part in parts:
if not part.strip():
continue # Skip empty parts
# If still too long, recurse with other separators
if len(part) > max_len e len (separadores)> 1: chunks.extend (recursive_chunking (parte, separadores[1:]max_len)) else: chunks.append (parte) retorna blusks chunks = recursive_chunking (documento, [‘\n\n’, ‘.’, ‘,’]100) Digite o modo de saída de tela cheia de tela cheia aqui estão os três primeiros pedaços: ‘\ nJohn Doe é o CEO da Examplecorp’ “” \ nhe é um engenheiro de software qualificado com foco em sistemas escaláveis “‘\ nin seu tempo de reposição, ele toca guitarra e lê o modo de ficção científica. De um modo geral, muitas vezes é útil levar em consideração a estrutura do documento ao executar o Chunking, especialmente ao trabalhar com formatos de documentos estruturados, como Markdown ou HTML.Por por exemplo, se tivermos um documento de marcação, podemos usar os cabeçalhos para dividi -lo em seções. Considere o seguinte documento de marcação: # Um documento de marcação ## Introdução Esta é a introdução do documento. ## Antecedentes Esta é a seção de plano de fundo do documento. ## Conclusão Esta é a conclusão do documento. Enter fullscreen mode Exit fullscreen mode We can use the headers to split the document into sections: def markdown_chunking(document): return document.split(“\n\n##”) chunks = markdown_chunking(document) Enter fullscreen mode Exit fullscreen mode A real implementation would be more complex and might account for headings of different levels, code blocks, and other constructs.Additionally, combining Markdown chunking Com Chunking recursivo, pode produzir mais pedaços granulares. Quando os documentos são estruturados de maneira limpa, as estratégias simples de chunking podem ser altamente eficazes. No entanto, a estrutura por si só não é suficiente. Embora esses métodos reconheçam a sintaxe do documento, eles não podem capturar seu significado. Se você achou isso útil, solte um ❤️ e pressione Siga para obter mais informações de desenvolvimento em seu feed!
Fonte













Publicar comentário