Eu dei uma promoção ao meu LLM: agora ele delega seu próprio trabalho
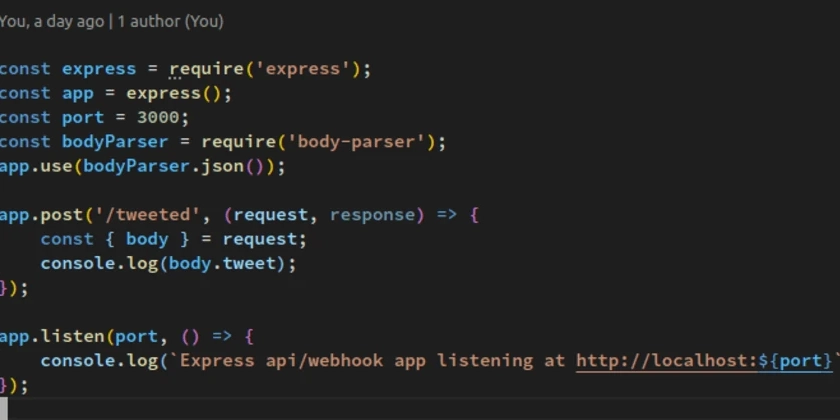
Modelos de idiomas grandes são poderosos, mas também são intensivos em recursos. Toda consulta, por mais simples que consome ciclos computacionais caros. Percebi que uma grande parte dos custos do meu servidor era do LLM respondendo repetidamente “Hello”, “Obrigado” e “OK”. Essas consultas são um desperdício. Eles não ensinam ao modelo nada de novo. Eles não exigem raciocínio complexo. Eles são pura dreno de recursos. Meu primeiro pensamento foi filtrá-los no lado do cliente. Mas isso cria uma tarefa manual – eu teria que atualizar constantemente a lista de frases simples. Essa abordagem não escala. Então, eu virei o problema de cabeça para baixo. E se o LLM pudesse resolver esse problema em si? A idéia principal é a seguinte: criei um sistema em que o próprio LLM decide quais consultas são simples demais para sua atenção e ensina um ajudante do lado do cliente a lidar com elas no futuro. A Arquitetura: Auto-Delegação Eu construí um projeto em torno desse conceito único, retirando tudo o que não é essencial de uma versão anterior. Possui apenas duas partes principais: o “professor” do lado do servidor (o LLM): o modelo principal e poderoso. Seu trabalho é lidar com tarefas complexas e-crucialmente-identificar consultas repetitivas de baixo valor. O “gatekeeper” do lado do cliente (o ajudante): um pequeno agente JavaScript de dependência zero de dependência no navegador. Ele intercepta toda a entrada do usuário e pede ajuda ao LLM apenas quando encontrar algo que não foi ensinado a lidar. Como o LLM descarrega seu trabalho na primeira vez em que um usuário envia uma consulta simples como “thx”, o gatekeeper não a reconhece e a encaminha para o LLM. O LLM sabe que “THX” é simples. Em vez de apenas enviar de volta uma resposta de texto, ele envia de volta uma carga útil especial do JSON, contendo um pedido direto: {“UserResponse”: “De nada!”, “LearningInstruction”: {“Command”: “Learn_simple_phrase”, “Query”: “thx”, “Response”: “Você é bem -vindo!” }} Digite o modo de saída de tela cheia de tela cheia. Esta assassinato de aprendizagem é a chave. É o LLM dizendo ao gatekeeper: “Eu respondi isso por você uma vez. Agora aprenda. A partir de agora, você lida com essa consulta. Não envie para mim novamente.” O gatekeeper recebe esse comando, salva a nova regra no localStorage do navegador e entrega a resposta ao usuário. O usuário não vê nada além de uma resposta rápida. Mas, em segundo plano, o sistema ficou mais inteligente e eficiente. Na próxima vez que o “THX” for enviado, o gatekeeper lida instantaneamente e o servidor nunca se incomoda. O LLM é ativamente, automaticamente e invisivelmente facilitando seu próprio trabalho. Não está sendo treinado por um humano; Está treinando seu próprio assistente para filtrar o barulho. Este projeto foi um exercício de minimalismo. Joguei fora uma complexa biblioteca de rede neural e outros recursos desnecessários para se concentrar apenas no aperfeiçoamento desse loop de autodescendência. O resultado é um sistema magro e poderoso que demonstra uma maneira mais inteligente de criar aplicativos de IA. Não precisamos apenas de modelos maiores; Precisamos de arquiteturas mais inteligentes, onde os modelos podem trabalhar juntos e otimizar seus próprios fluxos de trabalho. Confira a implementação completa no GitHub e veja a autodescendência em ação.
Fonte












Publicar comentário